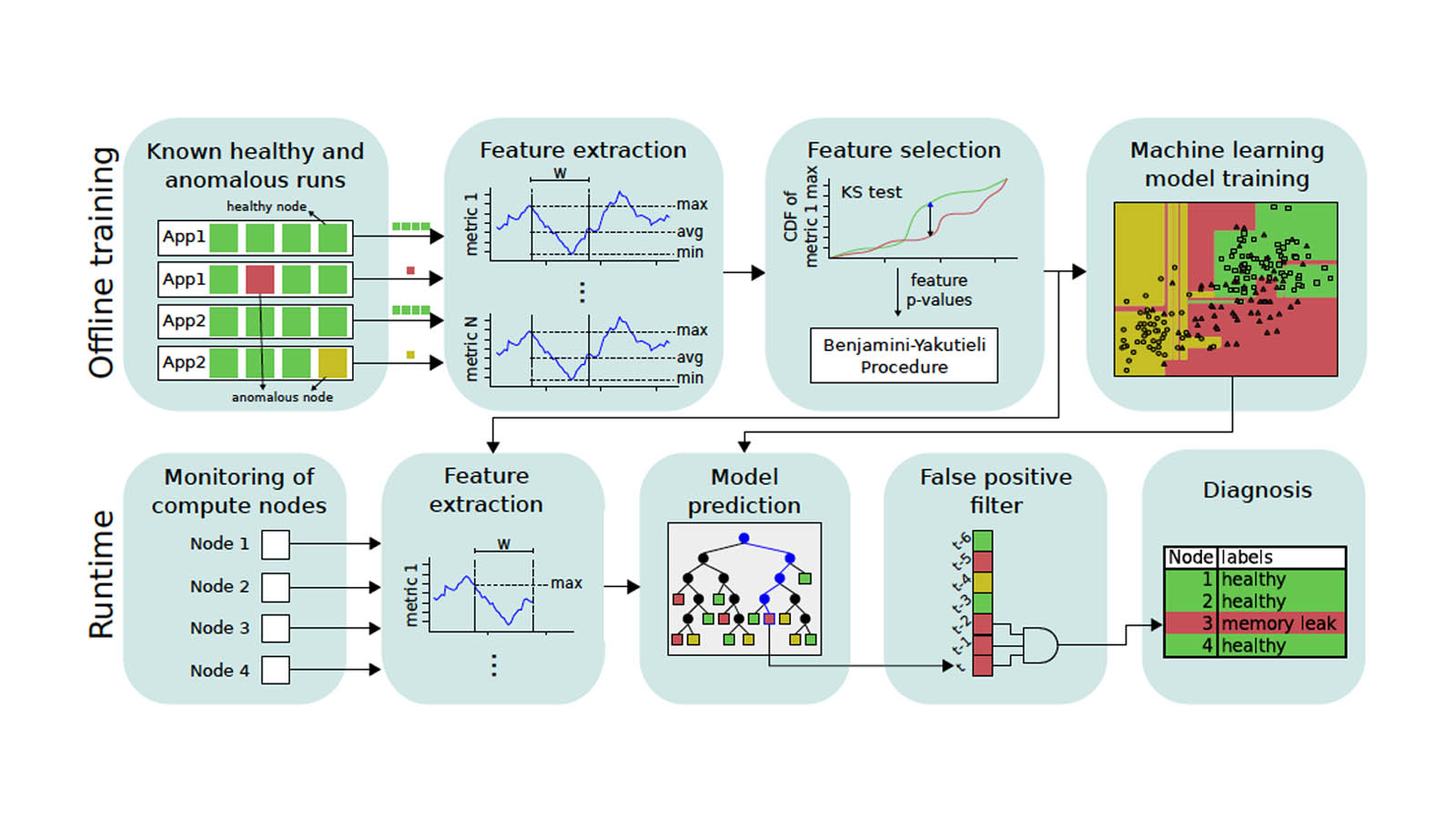
As the size and complexity of HPC systems increase, manual analysis methods relying on human experts have become increasingly limited in identifying root causes of performance problems (e.g., slowdowns) or improving resource management decisions. This talk introduces a set of novel machine learning frameworks that diagnose performance anomalies and identify applications running on supercomputers. We evaluate our frameworks on an HPC system and demonstrate that our approach outperforms current state-of-the-art techniques in detecting anomalies and applications, reaching an F-score over 0.97.